


18. 9. 2022 | 1022 x | Web
Často sa stane, že potrebujeme z fotografie na ktorej je odfotený text, alebo číslo získať tento údaj do textovej podoby a ďalej s ním pracovať. Ide o optické rozpoznávanie textu z obrázkov známe pod názvom Optical Character Recognition, v skratke OCR. V mnohých prípadoch nám postačuje takto spracovať jeden obrázok, pričom využijeme jednu z viacerých bezplatných služieb, ktoré nájdeme pri vyhľadávaní kľúčových slov ako FREE OCR. Existujú ale prípady, keď takto potrebujeme spracovať viac fotografií dávkovo a z časového hľadiska je nevyhovujúce postupovať jednotlivo. Napríklad fotografi pri fotografovaní športových udalostí odfotia za jeden deň množstvo športovcov, pričom každý ma na oblečení svoje číslo. A práve toto číslo je potrebné automaticky prečítať, zapísať do databázy s príslušnou fotografiou. Následne je možné podľa tohto čísla vyhľadávať konkrétneho športovca na záberoch a fotografiu napríklad kúpiť / stiahnuť, alebo s ňou inak ďalej pracovať.

Ukážka fotografie, kde športovci majú na oblečení svoje čísla. Automatické OCR by z tejto fotografie malo získať nasledovné údaje: 5373, 525, 5003, 5526, 5196. Podľa týchto čísel je potom možné vyhľadávanie športovca, ktorého chceme na fotografiách nájsť.
Optické rozoznávanie znakov
Existuje viacero spôsobov na prevod grafických znakov do ich editovateľnej podoby. V prostredí webových technológií to môže byť napríklad Tesseract OCR for PHP, ktorý nájdeme aj ako Composer knižnicu - https://github.com/thiagoalessio/tesseract-ocr-for-php. Tesseract nainštalujeme na web server prostredníctvom spustenia:
$ composer require thiagoalessio/tesseract_ocrV oficiálnej dokumentácii k tejto knižnici je pre Windows spomenutá inštalácia balíka Capture2Text s Chocolatey. Viac informácií o postupe nájdeme na stránkach tohto balíka:
https://community.chocolatey.org/packages/capture2text
Spustenie služby v skriptoch prostredí PHP na webe potom bude napríklad takto:
<?php
require_once 'vendor/autoload.php';
use thiagoalessioTesseractOCRTesseractOCR;
echo (new TesseractOCR('text.png'))
->run();
?>Ak súbor text.png vyzerá nasledovne, získame z neho tento text:

The quick brown fox
jumps over
the lazy dog.
V praxi je vhodné doplniť parameter jazyka, v ktorom je daný text na obrázku. Správnym nastavením dosiahneme lepšie výsledky OCR, napríklad pre anglický jazyk pridáme parameter:
->lang('eng')Existujú tiež viaceré on-line služby, ktoré disponujú API rozhraním, ktoré môžeme kedykoľvek použiť. Pre niektoré projekty a charakter vstupných obrázkov postačuje aj toto riešenie s knižnicou Tesseract OCR for PHP, ktorá je v podstate na ďalšie používanie po inštalácii a konfigurácii bezplatná. Niekedy je však toto OCR nedostatočné a nedokáže korektne rozpoznať číselné, alebo textové údaje. Vtedy je potrebné siahnuť po iných riešeniach, niekedy aj po platených službách, ktoré je možné integrovať cez API rozhranie. Fungujú veľmi dobre a presne a stále nejde o veľký náklad na mesačné používanie.
Web riešenie pre automatické rozpoznanie textu
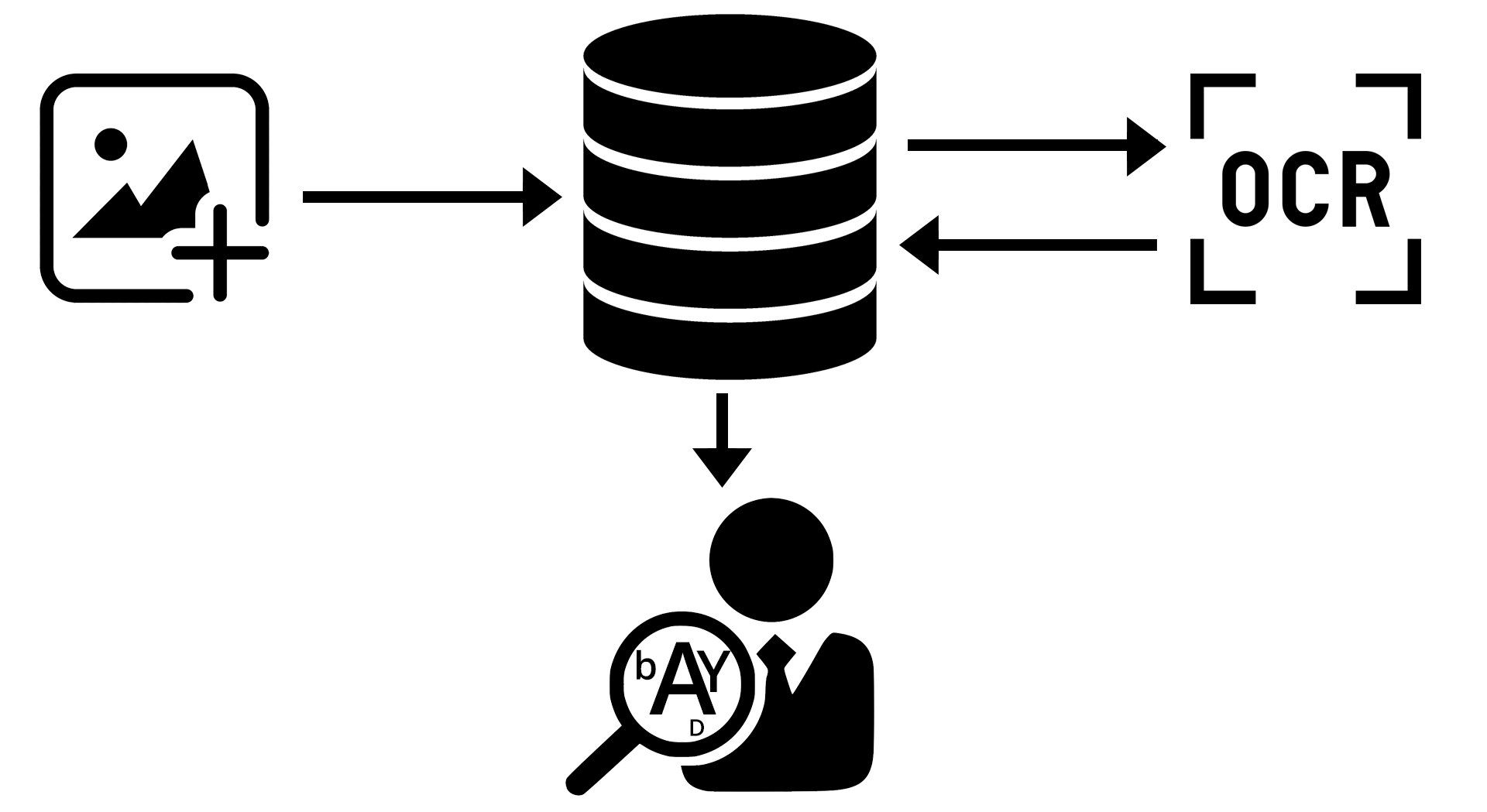
Celý systém môže mať nasledovnú architektúru, ako znázorňuje schéma nižšie. Vstupný formulár umožní nahrať jednu, alebo viacej fotografií do systému. Po nahratí všetkých fotografií sa spustí OCR analýza fotiek a ňou získané textové hodnoty sa zapíšu do databázy. Tým získame databázu fotografií s atribútom textu, ktorý bol rozpoznaný technológiou OCR. S takto obohatenou databázou je už ďalšia práca užívateľom jednoduchá, napríklad pre integráciu vyhľadávača, alebo systému na prezeranie fotiek.
Ak riešite OCR v prostredí webu, prípadne ak hľadáte podobné spracovanie pre váš projekt, kontaktujte ma, alebo napíšte do diskusie nižšie.
Pridať komentár k článku